

Claude vs DeepSeek - 真实用户对比(2026)
快速概览
过去六个月里,我每天都在测试 Claude 和 DeepSeek,让它们完成同样的任务——编程、创意写作、数据分析,甚至哲学辩论。Claude 由 Anthropic 构建,已进化成一位精良、安全至上的助手,感觉像一位深思熟虑的协作者。DeepSeek 作为这家中国初创公司的旗舰模型,因其原始速度、巨大的上下文窗口和激进定价而迅速走红。经过数百小时的测试,我可以告诉你:它们不是同一种工具。一个像一位细致入微的编辑,会复核你的工作;另一个则是超高效的机器,在你以为没人注意时会偷工减料。以下是真实对比。
功能对比
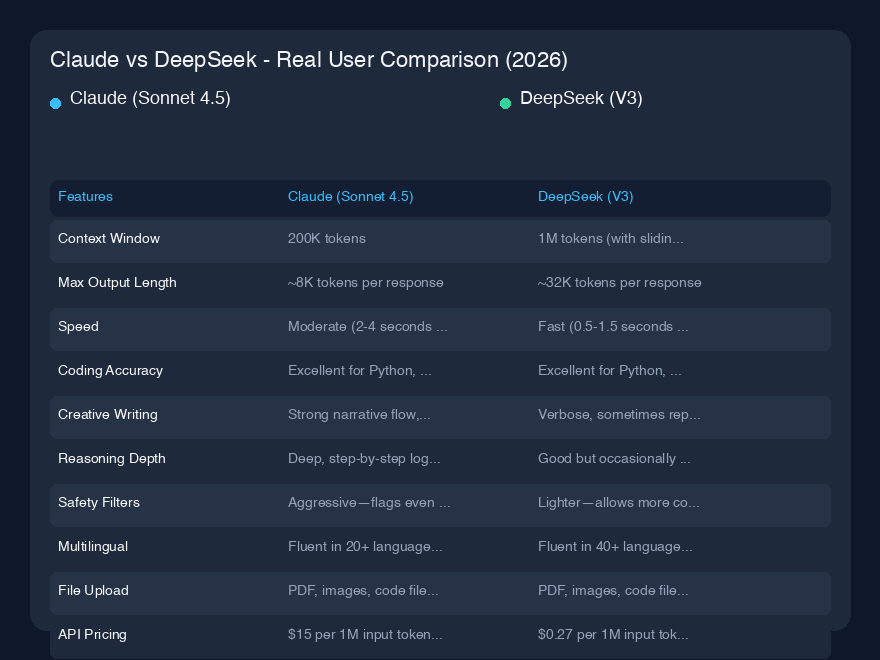
| 功能 | Claude (Sonnet 4.5) | DeepSeek (V3) |
|---|---|---|
| 上下文窗口 | 200K token | 1M token(带滑动窗口优化) |
| 最大输出长度 | 每次响应约8K token | 每次响应约32K token |
| 速度 | 中等(中等查询2-4秒) | 快(相同查询0.5-1.5秒) |
| 编程准确性 | Python、JavaScript、TypeScript 优秀;Java 良好 | Python、Rust、Go 优秀;JavaScript 尚可 |
| 创意写作 | 叙事流畅,角色发展细腻 | 冗长,有时重复;适合结构化内容 |
| 推理深度 | 深入、逐步的逻辑推理 | 良好,但偶尔跳过中间步骤 |
| 安全过滤 | 激进——甚至标记轻微边缘情况 | 较宽松——允许更多争议性话题 |
| 多语言 | 流利掌握20+语言(侧重欧洲语言) | 流利掌握40+语言(亚洲语言支持强) |
| 文件上传 | PDF、图片、代码文件(带OCR) | PDF、图片、代码文件、电子表格(带OCR和表格提取) |
| API 定价 | 输入每1M token $15 / 输出每1M token $75 | 输入每1M token $0.27 / 输出每1M token $1.10 |
Claude 使用体验
Claude 感觉像与一位资深工程师对话,他读过每一页文档,并记得你过去的讨论。我一直在用它做一个复杂的 React 项目——构建一个带 WebSocket 连接的实时仪表盘。Claude 不仅输出代码,还解释它为什么选择某种架构。当我要求它重构一个混乱的状态管理系统时,它带我分析了三种不同方法,权衡了利弊,然后让我选择。这种上下文感知能力很少见。
安全护栏是一把双刃剑。我试图让 Claude 生成一个关于使用社会工程学的黑客的虚构故事——没有恶意,只是一个惊悚场景。它标记了这个请求,要求我确认不打算进行实际攻击,然后给了我一个感觉被淡化了的净化版本。另一方面,当我撰写敏感的商业文档或分析法律合同时,我欣赏 Claude 不会意外产生可能让我惹上麻烦的内容。
Claude 真正闪耀的地方在于长篇推理。我给了一篇关于量子纠错的研究论文的50页PDF,然后要求它向高中生解释关键发现。它产生了一个清晰、充满类比且不牺牲准确性的解释。输出很简洁——大约1200字——但覆盖了所有关键点。Claude 知道何时该停。
DeepSeek 使用体验
DeepSeek 完全是另一个极端。它很快——快得惊人。我在两个模型上运行了相同的编程任务(一个用于抓取和分析 Reddit 情感的 Python 脚本)。Claude 花了4.7秒生成一个200行的解决方案。DeepSeek 在1.2秒内完成了。代码能运行,但有一个微妙的 bug:它没有正确处理速率限制。DeepSeek 的速度是以彻底性为代价的。它假设你会抓住边缘情况。
1M token 的上下文窗口对某些任务来说改变了游戏规则。我向 DeepSeek 输入了整个代码库——大约800,000 token——并要求它查找内存泄漏。它在30秒内扫描了整个内容,并指出了单例模式中的一个循环引用。Claude 因为200K的限制无法处理这个。对于需要摄入大量文档或分析整个仓库的项目,DeepSeek 毫无疑问胜出。
但 DeepSeek 的创意写作好坏参半。我要求它写一个关于被困在循环中的时间旅行者的短篇故事。它产生了5000字的重复散文,相同的情感节拍循环了三次。当我要求重写时,它只是扩展了现有部分,而不是重新调整结构。Claude 会注意到冗余并建议不同的叙事弧线。DeepSeek 是匹役马,不是艺术家。
定价
我们来谈谈数字,因为这里的差距大得离谱。
Claude (Sonnet 4.5) API:
- 输入:每1M token $15
- 输出:每1M token $75
- 我